Understanding the Different Types of AI Algorithms: Supervised, Unsupervised, and Reinforcement Learning


Artificial intelligence (AI) algorithms are a set of mathematical models and techniques that are used to enable computers to perform tasks that would normally require human intelligence, such as learning, problem-solving, and decision-making. These algorithms have become increasingly important in recent years as they have allowed computers to perform tasks that were previously thought to be beyond their capabilities, such as recognizing faces in photos, translating languages, and even beating humans at complex games like chess and Go.
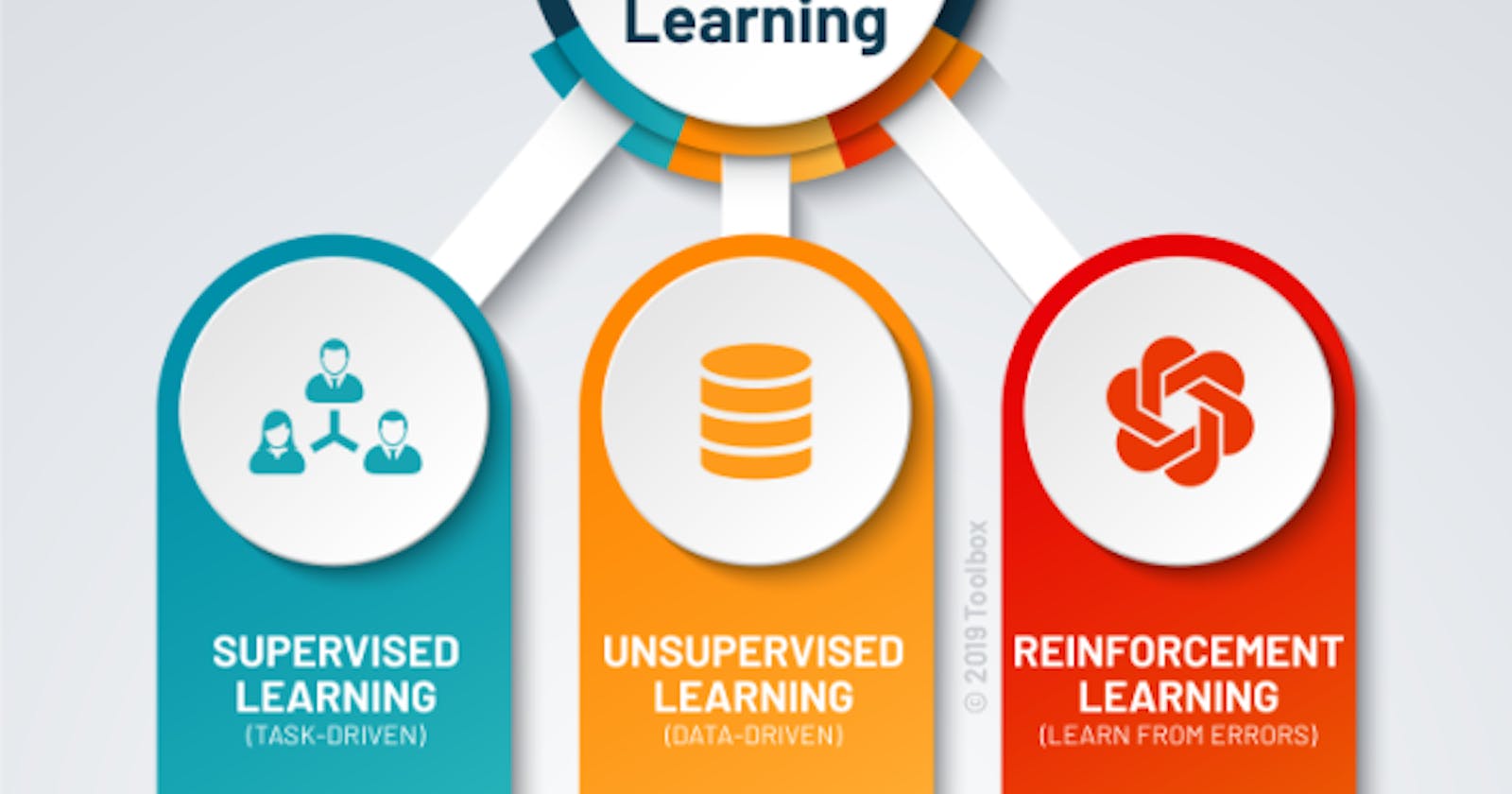
AI algorithms can be divided into several categories based on the type of task they are designed to perform. Some of the most common types of AI algorithms include supervised learning algorithms, unsupervised learning algorithms, and reinforcement learning algorithms. In this blog post, we will take a closer look at each of these types of algorithms and explore their characteristics and applications in more detail.
Supervised Learning:
Supervised learning is a type of artificial intelligence (AI) algorithm that involves training a model on a labelled dataset, where the input data and corresponding output labels are provided. The goal of supervised learning is to enable the model to make predictions about the output labels for new, unseen data based on the patterns it has learned from the training data.
Some examples of tasks that are commonly solved using supervised learning algorithms include:
Image classification: Given a set of labelled images of different objects, a supervised learning algorithm can learn to classify new images based on the features it has learned from the training data. For example, a model trained to classify images of cats and dogs can learn to distinguish between the two based on features such as fur colour and texture, ears, and tail shape.
Spam filtering: Given a set of labelled emails that are either spam or not spam, a supervised learning algorithm can learn to classify new emails as spam or not spam based on the words and patterns it has learned from the training data.
Predicting stock prices: Given a set of labelled stock price data over time, a supervised learning algorithm can learn to predict future stock prices based on patterns it has learned from the training data.
To train a supervised learning algorithm, the following steps are typically followed:
Collect and label a training dataset: The first step is to gather a large dataset of input data and corresponding output labels. The input data can be anything that the algorithm needs to learn from, such as images, text, or numerical data. The output labels are the correct answers that the algorithm is trying to predict, such as the class of an image or the spam/not spam label of an email.
Preprocess the data: The next step is to preprocess the data to make it suitable for training the algorithm. This may involve tasks such as normalizing the data, filling in missing values, or extracting relevant features.
Choose a model and training algorithm: The next step is to choose a model and training algorithm that will be used to learn from the training data. There are many different types of models and algorithms to choose from, each with its strengths and weaknesses.
Train the model: Once the model and training algorithm has been chosen, the model is trained on the training data using the chosen algorithm. The model adjusts its internal parameters based on the training data to make predictions that are as accurate as possible.
Evaluate the model: After training is complete, the model is evaluated on a separate dataset (called the test dataset) to see how well it performs on new, unseen data. The model's performance is usually measured using a metric such as accuracy, precision, or recall.
Fine-tune the model: If the model's performance on the test dataset is not satisfactory, the model can be fine-tuned by adjusting its hyperparameters (such as the learning rate or the number of hidden units) or by using more data to train it.
unsupervised learning:
Unsupervised learning is a type of artificial intelligence (AI) algorithm that involves training a model on an unlabeled dataset, where the input data is provided but the corresponding output labels are not. The goal of unsupervised learning is to enable the model to discover the patterns and relationships in the data on its own, without being told what to look for.
Some examples of tasks that are commonly solved using unsupervised learning algorithms include:
Anomaly detection: Given a dataset of normal data, an unsupervised learning algorithm can learn to identify data points that are unusual or abnormal. This can be useful for tasks such as detecting fraudulent transactions or identifying faulty equipment.
Clustering: Given a dataset of data points, an unsupervised learning algorithm can learn to group the data points into clusters based on their similarities. This can be useful for tasks such as customer segmentation or identifying similar documents.
Dimensionality reduction: Given a dataset of high-dimensional data, an unsupervised learning algorithm can learn to reduce the dimensionality of the data while preserving as much of the original information as possible. This can be useful for tasks such as visualizing data or improving the performance of other algorithms.
To train an unsupervised learning algorithm, the following steps are typically followed:
Collect a dataset: The first step is to gather a dataset of input data. The data can be anything that the algorithm needs to learn from, such as images, text, or numerical data.
Preprocess the data: The next step is to preprocess the data to make it suitable for training the algorithm. This may involve tasks such as normalizing the data, filling in missing values, or extracting relevant features.
Choose a model and training algorithm: The next step is to choose a model and training algorithm that will be used to learn from the data. There are many different types of models and algorithms to choose from, each with its strengths and weaknesses.
Train the model: Once the model and training algorithm has been chosen, the model is trained on the data using the chosen algorithm. The model adjusts its internal parameters based on the data to discover the patterns and relationships in the data.
Evaluate the model: After training is complete, the model's performance is usually evaluated by visualizing the results or by using a metric such as the silhouette score.
Fine-tune the model: If the model's performance is not satisfactory, the model can be fine-tuned by adjusting its hyperparameters or by using more data to train it.
reinforcement learning:
Reinforcement learning is a type of artificial intelligence (AI) algorithm that involves training a model to make decisions in an environment to maximize a reward. The model learns by taking actions and receiving feedback in the form of rewards or punishments and adjusts its behaviour accordingly.
Some examples of tasks that are commonly solved using reinforcement learning algorithms include:
Game playing: Given a set of rules for a game, a reinforcement learning algorithm can learn to play the game by taking actions and receiving rewards or punishments based on the outcomes of the actions. For example, a reinforcement learning algorithm can learn to play a game of chess by making moves that lead to winning positions and avoiding moves that lead to losing positions.
Robot control: Given a set of actions that a robot can take and a set of goals that the robot is trying to achieve, a reinforcement learning algorithm can learn to control the robot by taking actions and receiving rewards or punishments based on the outcomes of the actions. For example, a reinforcement learning algorithm can learn to navigate a robot through a maze by taking actions that lead the robot closer to the goal and avoiding actions that lead the robot farther away from the goal.
Recommendation systems: Given a set of rules for recommending items to users, a reinforcement learning algorithm can learn to make recommendations by taking actions (such as displaying a recommendation) and receiving rewards or punishments based on the outcomes of the actions (such as whether the user clicks on the recommendation).
Summary:
Algorithm Type | Characteristics | Applications |
|---|---|---|
Supervised Learning | Trained on labelled data | Image classification, spam filtering, predicting stock prices |
Unsupervised Learning | Trained on unlabeled data | Anomaly detection, clustering, dimensionality reduction |
Reinforcement Learning | Learns through trial and error to maximize a reward | A game playing, robot control, recommendation systems |
Some Limitations and challenges of AI algorithms:
Artificial intelligence (AI) algorithms are a powerful tool for enabling computers to perform tasks that require human-like intelligence, such as learning, problem-solving, and decision-making. However, AI algorithms also have several limitations and challenges that need to be considered when using them.
Some of the main limitations and challenges of AI algorithms include:
Data quality: AI algorithms rely on high-quality data to learn from, and the accuracy of the results produced by the algorithms is directly related to the quality of the data. Poor quality data, such as data with missing values or incorrect labels, can lead to inaccurate or misleading results.
Bias: AI algorithms can be biased if the data they are trained on is biased. For example, if a model is trained on a predominantly male dataset, it may be biased towards classifying individuals as male. This can lead to unfair and discriminatory outcomes.
Interpretability: Many AI algorithms, particularly deep learning algorithms, are difficult to interpret and understand. This can make it challenging to understand how the algorithms are making their decisions and to identify and correct errors.
Ethical concerns: AI algorithms can raise ethical concerns, particularly when they are used in decision-making processes that affect people's lives, such as hiring, lending, and healthcare. These concerns include issues such as fairness, accountability, and transparency.
Computational power: Some AI algorithms, particularly deep learning algorithms, require significant computational power to train and run. This can be a barrier for organizations with limited resources or for applications that require real-time processing.
Overall, AI algorithms have the potential to revolutionize many fields and bring significant benefits, but it is important to carefully consider their limitations and challenges to use them effectively and ethically.
Some benefits of understanding the different types of AI algorithms and their capabilities:
Choosing the right algorithm for the task: Different types of AI algorithms are suited to different types of tasks. For example, supervised learning algorithms are well-suited for tasks that involve predicting outputs based on labelled training data, while unsupervised learning algorithms are well-suited for tasks that involve discovering patterns in unlabeled data. Choosing the right algorithm for a particular task is crucial to achieving the desired results.
Avoiding common pitfalls: Several common pitfalls can arise when using AI algorithms, such as bias, overfitting, and underfitting. Understanding the characteristics and capabilities of the different types of algorithms can help to avoid these pitfalls and ensure that the algorithms are used effectively.
Evaluating the results: Understanding the different types of AI algorithms and their capabilities can also help to evaluate the results produced by the algorithms. For example, if a supervised learning algorithm
Conclusion:
In conclusion, artificial intelligence (AI) algorithms are a set of mathematical models and techniques that are used to enable computers to perform tasks that would normally require human intelligence, such as learning, problem-solving, and decision-making. There are several types of AI algorithms, including supervised learning, unsupervised learning, and reinforcement learning, each with its own characteristics and capabilities.
Understanding the different types of AI algorithms and their capabilities is crucial in order to make informed decisions about their use. Each type of algorithm has its own strengths and weaknesses, and choosing the right algorithm for a particular task is important to achieve the desired results.
While AI algorithms have the potential to revolutionize many fields and bring significant benefits, it is also important to consider their limitations and challenges, such as data quality, bias, interpretability, ethical concerns, and computational power. By understanding these limitations and challenges, we can use AI algorithms effectively and ethically to bring about positive change.