


Table of contents
- Best Practices for Prompt Engineering
- Iterative Prompt Development
- Asking for a Structural Output
- Chain-of-Thought Reasoning
- Few-shot Learning
- Summarizing Best Practices
- Prompt Engineering Course by DeepLearning.AI and OpenAI
- Building the LLM-based Application with OpenAI API and Streamlit
- Generating OpenAI Key
- Estimating the Costs with Tokenizer Playground
- Side note: Tokenization for Different Languages
- Cost vs Performance
- Project
- Conclusion
Prompt engineering refers to the process of creating instructions called prompts for Large Language Models (LLMs), such as OpenAI’s ChatGPT. With the immense potential of LLMs to solve a wide range of tasks, leveraging prompt engineering can empower us to save significant time and facilitate the development of impressive applications. It holds the key to unleashing the full capabilities of these huge models, transforming how we interact and benefit from them.
In this article, I tried to summarize the best practices of prompt engineering to help you build LLM-based applications faster. While the field is developing very rapidly, the following “time-tested” :) techniques tend to work well and allow you to achieve fantastic results. In particular, we will cover:
The concept of iterative prompt development, using separators and structural output;
Chain-of-Thoughts reasoning;
Few-shot learning.
Together with intuitive explanations, I’ll share both hands-on examples and resources for future investigation.
Then we’ll explore how you can build a simple LLM-based application for local use using OpenAI API for free. We will use Python to describe the logic and Streamlit library to build the web interface.
Let’s start!
Best Practices for Prompt Engineering
In this article, I will interact with ChatGPT through both the web interface and API. The gpt-3.5-turbo model I’ll use is the one behind ChatGPT, so you can experiment with your prompts right in the browser.
One important thing to note here is that ChatGPT is not only LLM; as you probably know, it’s also a SFT (Supervised Fine-Tuning) model that was further finetuned with Reinforcement Learning from Human Feedback (RLHF). While many developers currently utilize OpenAI’s models for experimental projects and personal exploration, other models may be more appropriate for deployment in production settings within large corporations due to privacy and other reasons.
If you want to know why base models (such as GPT-3, Chinchilla, LLaMA) do not function in the same way as fine-tuned and RLHF-trained assistants (e.g., ChatGPT, Koala, Alpaca), there is a talk by Andrej Karpathy about training and using GPT-like models. I highly recommend checking it out for a deeper understanding, and it is just 40 minutes long. For a summary, take a look at this Twitter thread.
Now let’s dive into best practices for prompting instruction-tuned LLMs!
Iterative Prompt Development
Just as any machine learning model is built through an iterative process, effective prompts are also constructed through a similar iterative approach. Even the most talented developer may not create the perfect prompt on their first attempt, so be prepared for the reality that you may need dozens of attempts to achieve the desired goal.
Building data-based applications is always an iterative process. Public domain
It’s always better to understand things through examples. Let’s start building a system to extract information from a job description. The sample job description we’ll be using in the examples is the following Machine Learning Engineer job posting from LinkedIn.

The initial prompt can be as simple as asking the model to extract specific information. Additionally, I’ll use delimiters (you can learn more about it in the ChatGPT Prompt Engineering for Developers course I will mention later). While it’s unlikely that a local application would be susceptible to prompt injection attacks, it’s just good practice.
def prompt_v1(job_description):
""" Get the prompt for the given job description, v1 """
prompt = "Given the job description separated by <>, extract useful information.\n"
prompt += f"<{job_description}>"
return prompt

Output for a prompt v1. Image by Author created using ChatGPT
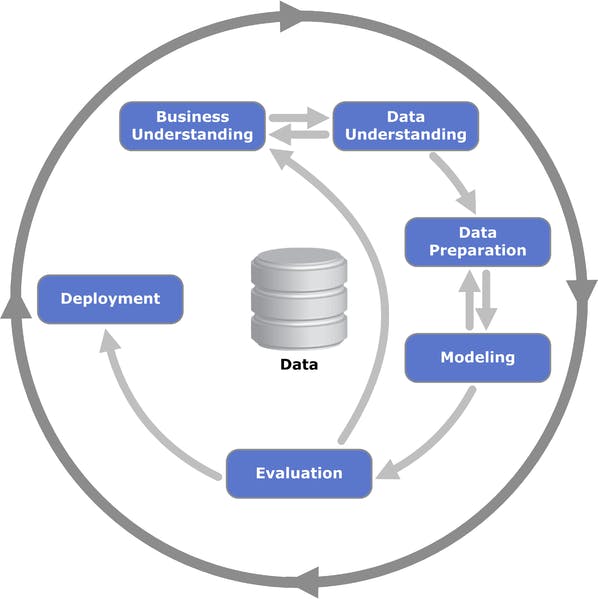
Hmm, that’s not very helpful. We need to be more specific about what we want from the model. Let’s ask it to extract the job title, company name, key skills required, and a summarized job description.
Remember that this is just an example, and you can design your prompts to extract as much information as you want: degree, years of experience required, location, etc.
def prompt_v2(job_description):
""" Get the prompt for the given job description, v2 (specify outputs) """
prompt = "Given the job description separated by <>, extract useful information. " \
"Output job title, company, key skills, and summarized job description.\n"
prompt += f"<{job_description}>"
return prompt

Output for a prompt v2. Image by Author created using ChatGPT
Looking better! To make the output more compact and concise, let’s ask the model to output skills as a list and a more brief summary of the job description.
def prompt_v3(job_description):
""" Get the prompt for the given job description, v3 (add clarifications for job description summary) """
prompt = "Given the job description separated by <>, extract useful information. " \
"Output job title, company, key skills as a list separated by commas, " \
"and summarized job description (use at least 30 words and focus on day-to-day responsibilities).\n"
prompt += f"<{job_description}>"
return prompt
Output for a prompt v3. Image by Author created using ChatGPT
It’s a significant improvement from our initial attempt, isn’t it? And we accomplish this in just two iterations! So, don’t lose hope when things don’t go smoothly initially. Keep guiding the model, experiment, and you’ll certainly achieve success.
Asking for a Structural Output
The second point I would like to discuss is asking the model to output results in some expected structural format. While it may not be as critical for interacting with LLM through the web interface (e.g. as we do with ChatGPT), it becomes extremely useful for LLM-based applications since the process of parsing the results is much easier.
One common practice is to use formats like JSON or XML and define specific keys to organize output data. Let’s modify our prompt to show the model expected JSON structure.
from textwrap import dedent
def prompt_v4(job_description):
""" Get the prompt for the given job description, v4 (JSON output) """
# using textwrap.dedent to unindent strings, e.g. ignore tabs
prompt = dedent("""\
Given the job description separated by <>, extract useful information.
Format your response as JSON with the following structure:
{
"job_title": Job title,
"company": Company,
"key_skills": ["list", "of", "key", "skills"],
"job_description": Job summary
}
For job summary use at least 30 words and focus on day-to-day responsibilities.
""")
prompt += f"<{job_description}>"
return prompt

Output for a prompt v4, asking for JSON output. Image by Author created using ChatGPT
Such output is much easier to parse and process in the following logic of your application.
It’s worth saying a few words about the development of this direction. Some tools are aiming to strictly fit the model’s output into a given format, which can be extremely useful for some tasks. Just look at the examples below!
One of the possible applications is the generation of a large amount of content in a specific format (e.g. game characters' information using guidance).

Generating game character info in JSON. Gif from guidance GitHub repo
Languages like LMQL bring a programming-like approach to prompting language models. As these tools continue to evolve and improve, they have the potential to revolutionize how we interact with LLMs, resulting in more accurate and structured responses.
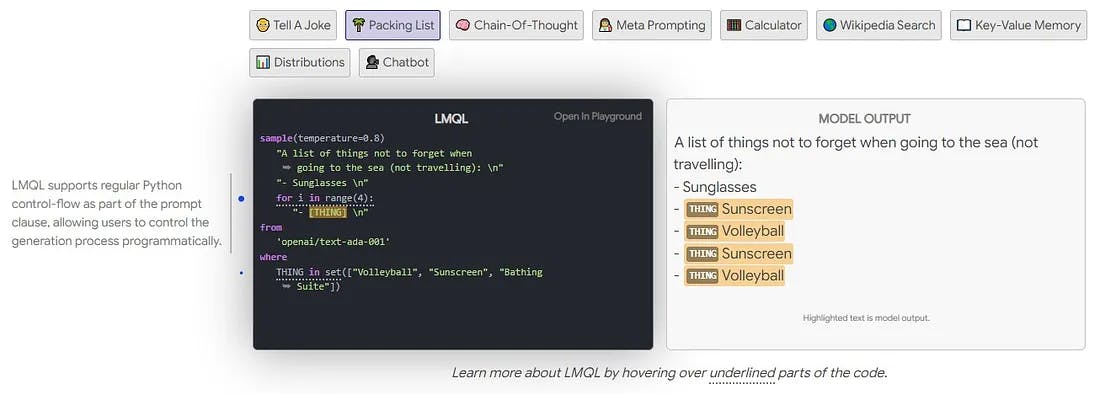
LMQL query example. Screenshot of the LMQL webpage, see more examples here
Chain-of-Thought Reasoning
Chain-of-Thought (CoT) reasoning was discovered to be very helpful for tasks that require… well, reasoning. So if you have the opportunity to solve the task by breaking it into multiple simpler steps that can be a great approach for LLM.
Take a look at the example from the original paper. By splitting the problem into smaller steps and providing explicit instructions, we can assist the model in producing correct outputs.
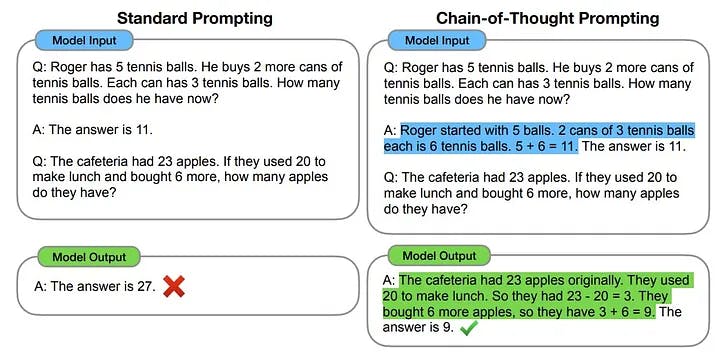
Introducing CoT prompting. Figure 1 from the Chain-of-Thought Prompting Elicits Reasoning in LLMs paper
Interestingly, it emerges later that appending a straightforward and magic “let’s think step by step” at the end of a prompt can improve results — this technique is known as zero-shot CoT. So, compose prompts that allow the model to “think out loud” since it does not have any other ability to express thoughts other than generate tokens.
The best zero-shot CoT prompt so far is “Let’s work this out in a step by step way to be sure we have the right answer”.

Best zero-shot prompts. Table 7 from the LLMs Are Human-Level Prompt Engineers paper
More sophisticated approaches to solving even more complex tasks are now being actively developed. While they significantly outperform in some scenarios, their practical usage remains somewhat limited. I will mention two such techniques: self-consistency and the Tree of Thoughts.
The authors of the self-consistency paper offered the following approach. Instead of just relying on the initial model output, they suggested sampling multiple times and aggregating the results through majority voting. By relying on both intuition and the success of ensembles in classical machine learning, this technique enhances the model’s robustness.
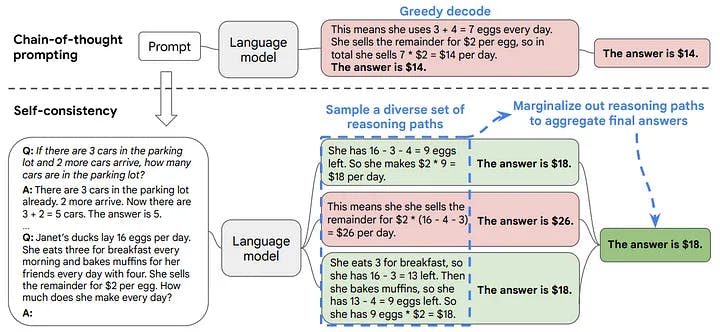
Self-consistency. Figure 1 from the Self-Consistency Improves CoT Reasoning in Language Models paper
You can also apply self-consistency without implementing the aggregation step. For tasks with short outputs ask the model to suggest several options and choose the best one.
Tree of Thoughts (ToT) takes this concept a stride further. It puts forward the idea of applying tree-search algorithms for the model’s “reasoning thoughts”, essentially backtracking when it stumbles upon poor assumptions.
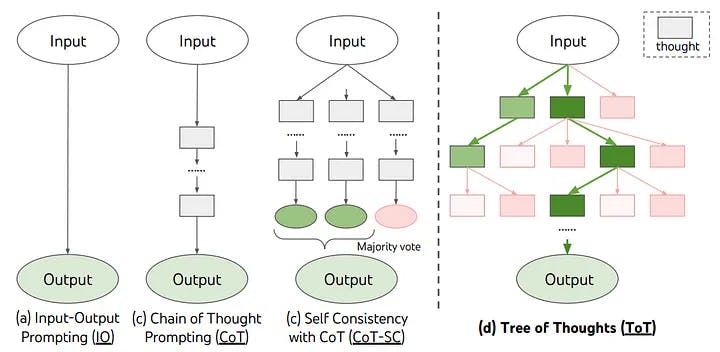
Tree of Thoughts. Figure 1 from the Tree of Thoughts: Deliberate Problem Solving with LLMs paper
If you are interested, check out Yannic Kilcher’s video with a ToT paper review.
For our particular scenario, utilizing Chain-of-Thought reasoning is not necessary, yet we can prompt the model to tackle the summarization task in two phases. Initially, it can condense the entire job description, and then summarize the derived summary with a focus on job responsibilities.
from textwrap import dedent
def prompt_v5(job_description):
""" Get the prompt for the given job description, v5 (add CoT for summaries) """
# using textwrap.dedent to unindent strings, e.g. ignore tabs
prompt = dedent("""\
Given the job description separated by <>, extract useful information.
Format your response as JSON with the following structure:
{
"job_title": Job title,
"company": Company,
"key_skills": ["list", "of", "key", "skills"],
"job_description_summary": Job description summary,
"job_responsibilities_summary": Job responsibilities summary
}
To effectively complete the summarization, follow these steps:
- First, summarize the whole job description and write it as value for "job_description" key
- Then, summarize the job description summary with a focus on day-to-day responsibilities
""")
prompt += f"<{job_description}>"
return prompt
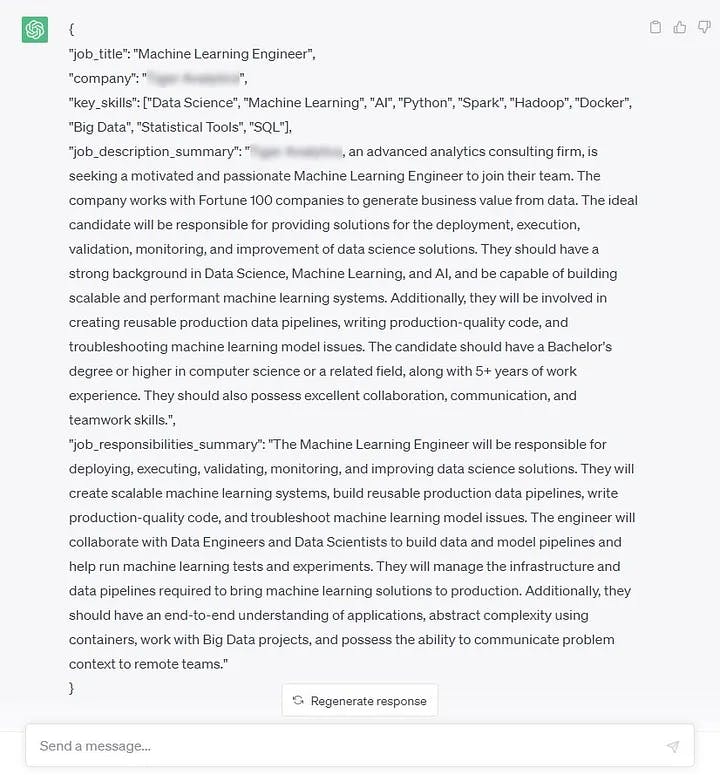
Output for a prompt v5, containing step-by-step instructions. Image by Author created using ChatGPT
In this particular example, the results did not show significant changes, but this approach works very well for most tasks.
Few-shot Learning
The last technique we will cover is called few-shot learning, also known as in-context learning. It’s as simple as incorporating several examples into your prompt to provide the model with a clearer picture of your task.
These examples should not only be relevant to your task but also diverse to encapsulate the variety in your data. “Labeling” data for few-shot learning might be a bit more challenging when you’re using CoT, particularly if your pipeline has many steps or your inputs are long. However, typically, the results make it worth the effort. Also, keep in mind that labelling a few examples is far less expensive than labelling an entire training/testing set as in traditional ML model development.
If we add an example to our prompt, it will understand the requirements even better. For instance, if we demonstrate that we’d prefer the final summary in bullet-point format, the model will mirror our template.
This prompt is quite overwhelming, but don’t be afraid: it is just a previous prompt (v5) and one labelled example with another job description in the For example: 'input description' -> 'output JSON' format.
from textwrap import dedent
def prompt_v6(job_description):
""" Get the prompt for the given job description, v6 (add example) """
# using textwrap.dedent to unindent strings, e.g. ignore tabs
prompt = dedent("""\
Given the job description separated by <>, extract useful information.
Format your response as JSON with the following structure:
{
"job_title": Job title,
"company": Company,
"key_skills": ["list", "of", "key", "skills"],
"job_description_summary": Job description summary,
"job_responsibilities_summary": Job responsibilities summary
}
To effectively complete the summarization, follow these steps:
- First, summarize the whole job description and write it as value for "job_description" key
- Then, summarize the job description summary with a focus on day-to-day responsibilities
For example:
'
KUBRA is in growth mode and currently seeking a Machine Learning Engineer to join our Data Analytics Team!
As a Machine Learning Engineer, you will be working on designing and maintaining the Machine Learning algorithms that will be used to extract value out of our data. The best part? You will also be collaborating with BI Analysts, and Data Engineers to introduce new data on machine learning standards and best practices with KUBRA!
What will you be involved in?
- Introduce machine learning standards and best practices to KUBRA.
- Build scalable machine learning architecture and automate machine learning operations.
- Offer data-driven insights that provide value to both internal and external customers.
- Foster an environment that emphasizes trust, open communication, creative thinking, and cohesive team effort.
- Build and maintain machine learning solutions in production.
- The initial models may be against data in our on-premise infrastructure. As the data engineers migrate more of our data to AWS, the ML model will be against data in AWS.
What type of person are you?
- Excellent written and verbal communication skills and an ability to maintain a high degree of professionalism in all client communications.
- Ability to influence others, build relationships, manage conflicts, and handle negotiations.
- Excellent organization, time management, problem-solving, and analytical skills.
- Proactive mindset and ability to work independently in a fast-paced environment focused on results.
- Ability to handle pressure.
What skills do you bring? (Hard Skills)
- Minimum of 2 to 3 years of experience building machine learning pipelines.
- An undergraduate or masters degree in Computer Science, Statistics, Analytics, or a similar discipline
- Sound knowledge of machine learning lifecycle from data gathering to model deployment.
- Experience deploying machine learning models into a production environment.
- Demonstrable experience with regression, clustering, and classification algorithms.
- Preferable to have experience with one or more of Data tools, Databricks, Snowflake, SQL, R, Python, Spark.
- Knowledge in one of AzureML or AWS Sagemaker desirable.
- Experience in CI/CD and good understanding of containerization concepts.
- Experience in building API’s for Model Serving is an asset.
What you can expect from us?
- Award-winning culture that fosters growth, diversity and inclusion for all
- Paid day off for your birthday
- Access to LinkedIn learning courses
- Continued education with our education reimbursement program
- Flexible schedules
- Two paid days for volunteer opportunities
- Well-Being Days!
'
->
'
{
"job_title": "Machine Learning Engineer",
"company": "KUBRA",
"key_skills": ["Databricks", "Snowflake", "SQL", "R", "Python", "Spark", "AzureML", "AWS"],
"job_description_summary": "KUBRA is seeking a Machine Learning Engineer to join their Data Analytics Team. The role involves designing and maintaining machine learning algorithms to extract value from data. Collaboration with BI Analysts and Data Engineers is required to introduce new data and best practices. The engineer will build scalable machine learning architecture, automate machine learning operations, offer data-driven insights, and ensure trust, open communication, and a cohesive team effort.",
"job_responsibilities_summary": "- Working on designing and maintaining the Machine Learning algorithms;\n - Collaborating with BI Analysts, and Data Engineers to introduce new data on machine learning standards and best practices"
}
'
""")
prompt += f"<{job_description}>"
return prompt
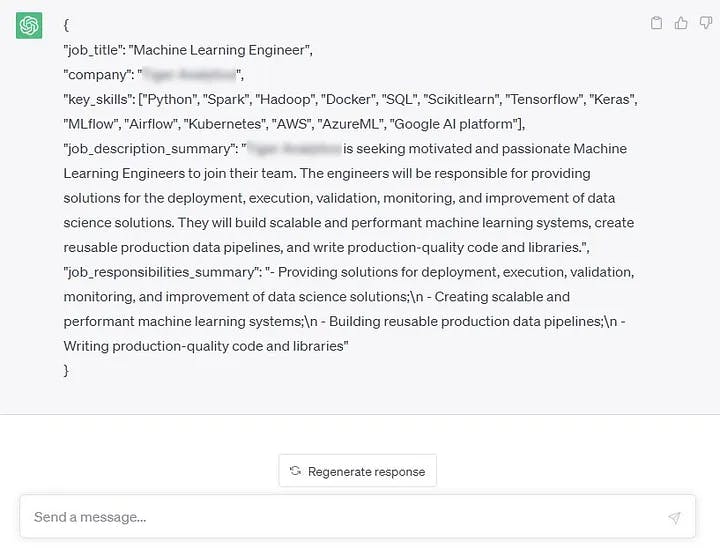
Output for a prompt v6, containing an example. Image by Author created using ChatGPT
Summarizing Best Practices
To summarize the best practices for prompt engineering, consider the following:
Don’t be afraid to experiment. Try different approaches and iterate gradually, correcting the model and taking small steps at a time;
Use separators in input (e.g. <>) and ask for a structured output (e.g. JSON);
Provide a list of actions to complete the task. Whenever feasible, offer the model a set of actions and let it output its “internal thoughts”;
In case of short outputs ask for multiple suggestions;
Provide examples. If possible, show the model several diverse examples that represent your data with the desired output.
I would say that this framework offers a sufficient basis for automating a wide range of day-to-day tasks, like information extraction, summarization, text generation such as emails, etc. However, in a production environment, it is still possible to further optimize models by fine-tuning them on specific datasets to further enhance performance. Additionally, there is rapid development in the plugins and agents, but that’s a whole different story altogether.
Prompt Engineering Course by DeepLearning.AI and OpenAI
Along with the earlier-mentioned talk by Andrej Karpathy, this blog post draws its inspiration from the ChatGPT Prompt Engineering for Developers course by DeepLearning.AI and OpenAI. It’s free, takes just a couple of hours to complete, and, my personal favourite, it enables you to experiment with the OpenAI API without even signing up!
That’s a great playground for experimenting, so definitely check it out.
Building the LLM-based Application with OpenAI API and Streamlit
Wow, we covered quite a lot of information! Now, let’s move forward and start building the application using the knowledge we have gained.
Generating OpenAI Key
To get started, you’ll need to register an OpenAI account and create your API key. OpenAI currently offers $5 of free credit for 3 months to every individual. Follow the introduction to the OpenAI API page to register your account and generate your API key.
Once you have a key, create an OPENAI_API_KEY environment variable to access it in the code with os.getenv('OPENAI_API_KEY').
Estimating the Costs with Tokenizer Playground
At this stage, you might be curious about how much you can do with just a free trial and what options are available after the initial three months. It’s a pretty good question to ask, especially when you consider that LLMs cost millions of dollars!
Of course, these millions are about training. It turns out that the inference requests are quite affordable. While GPT-4 may be perceived as expensive (although the price is likely to decrease), gpt-3.5-turbo (the model behind default ChatGPT) is still sufficient for the majority of tasks. In fact, OpenAI has done an incredible engineering job, given how inexpensive and fast these models are now, considering their original size in billions of parameters.
The gpt-3.5-turbo model comes for $0.002 per 1,000 tokens.
But how much is it? Let’s see. First, we need to know what is a token. In simple terms, a token refers to a part of a word. In the context of the English language, you can expect around 14 tokens for every 10 words.
To get a more accurate estimation of the number of tokens for your specific task and prompt, the best approach is to give it a try! Luckily, OpenAI provides a tokenizer playground that can help you with this.
Side note: Tokenization for Different Languages
Due to the widespread use of English on the Internet, this language benefits from the most optimal tokenization. As highlighted in the “All languages are not tokenized equal” blog post, tokenization is not a uniform process across languages, and certain languages may require a greater number of tokens for representation. Keep this in mind if you want to build an application that involves prompts in multiple languages, e.g. for translation.
To illustrate this point, let’s take a look at the tokenization of pangrams in different languages. In this toy example, English required 9 tokens, French — 12, Bulgarian — 59, Japanese — 72, and Russian — 73.
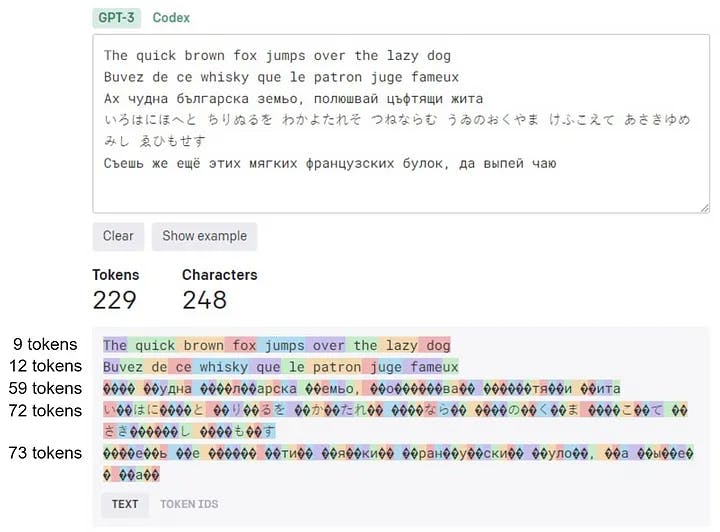
Tokenization for different languages. Screenshot of the OpenAI tokenizer playground
Cost vs Performance
As you may have noticed, prompts can become quite lengthy, especially when incorporating examples. By increasing the length of the prompt, we potentially enhance the quality, but the cost grows at the same time as we use more tokens.
Our latest prompt (v6) consists of approximately 1.5k tokens.

Tokenization of the prompt v6. Screenshot of the OpenAI tokenizer playground
Considering that the output length is typically the same range as the input length, we can estimate an average of around 3k tokens per request (input tokens + output tokens). By multiplying this number by the initial cost, we find that each request is about $0.006 or 0.6 cents, which is quite affordable.
Even if we consider a slightly higher cost of 1 cent per request (equivalent to roughly 5k tokens), you would still be able to make 100 requests for just $1. Additionally, OpenAI offers the flexibility to set both soft and hard limits. With soft limits, you receive notifications when you approach your defined limit, while hard limits restrict you from exceeding the specified threshold.
For local use of your LLM application, you can comfortably configure a hard limit of $1 per month, ensuring that you remain within budget while enjoying the benefits of the model.
Project
Information extraction system from job descriptions:
Now, let’s build a web interface to interact with the model programmatically. Let’s now create a simple template for our LLM-based application.
Firstly, we need the logic that will handle the communication with the OpenAI API. In the example below, I consider generate_prompt()function to be defined and return the prompt for a given input text (e.g. similar to what you saw before).
def ask_chatgpt(input_text: str) -> str:
""" Call OpenAI's gpt-3.5-turbo model API with prompt by 'generate_prompt()' function """
openai.api_key = os.getenv('OPENAI_API_KEY')
prompt = generate_prompt(input_text)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message["content"]
call_openai_api.py hosted with ❤ by GitHub
And that’s it! Know more about different parameters in OpenAI’s documentation, but things work well just out of the box.
Having this code, we can design a simple web app. We need a field to enter some text, a button to process it, and a couple of output widgets. I prefer to have access to both the full model prompt and output for debugging and exploring reasons.
The code for the entire application will look something like this and can be found in this GitHub repository. I have added a placeholder function called toy_ask_chatgpt() since sharing the OpenAI key is not a good idea. Currently, this application simply copies the prompt into the output.
import json
import os
import time
from textwrap import dedent
import openai
import streamlit as st
def generate_prompt(job_description: str) -> str:
"""
Get the information extraction prompt for the given job description:
- Asking for JSON output
- Keys are: job_title, company, key_skills (as list),
job_description_summary and job_responsibilities_summary
- Asking to complete summarization in two steps (CoT)
"""
# using textwrap.dedent to unindent strings, e.g. ignore tabs
prompt = dedent("""\
Given the job description separated by <>, extract useful information.
Format your response as JSON with the following structure:
{
"job_title": Job title,
"company": Company,
"key_skills": ["list", "of", "key", "skills"],
"job_description_summary": Job description summary,
"job_responsibilities_summary": Job responsibilities summary
}
To effectively complete the summarization, follow these steps:
- First, summarize the whole job description and write it as value for "job_description" key
- Then, summarize the job description summary with a focus on day-to-day responsibilities
""")
prompt += f"<{job_description}>"
return prompt
def ask_chatgpt(input_text: str) -> str:
""" Call OpenAI's gpt-3.5-turbo model API with prompt by 'generate_prompt()' function """
openai.api_key = os.getenv('OPENAI_API_KEY')
prompt = generate_prompt(input_text)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message["content"]
def toy_ask_chatgpt(input_text: str) -> str:
""" Try to call 'ask_chatgpt()' function and returns the same result if OpenAI key is not valid """
try:
return ask_chatgpt(input_text)
except openai.error.AuthenticationError:
time.sleep(2) # wait two seconds
return "OpenAI key is not valid. Input was:\n\n" + generate_prompt(input_text)
def main():
""" Build Streamlit app """
st.header("LLM-based application template with Streamlit")
st.subheader("Information extraction system from job descriptions")
with open('sample_job_description.txt', 'r') as f:
sample_job_description = f.read()
input_text = st.text_area('Enter job description', height=500, value=sample_job_description)
if st.button('Extract information', use_container_width=True):
with st.spinner('In progress...'):
# replace with 'ask_chatgpt' if you have configured your key
model_output = toy_ask_chatgpt(input_text)
with st.expander("Input prompt", expanded=False):
st.text(generate_prompt(input_text))
st.subheader("Full model output")
try:
model_output = json.loads(model_output)
st.json(model_output)
except json.JSONDecodeError:
st.text(model_output)
if __name__ == "__main__":
main()
streamlit_app.py hosted with ❤ by GitHub
Without defining functions and placeholders, it is only about 50 lines of code!


Conclusion
In this blog post, I listed several best practices for prompt engineering. We discussed iterative prompt development, the use of separators, requesting structural output, Chain-of-Thought reasoning, and few-shot learning. I also provided you with a template to build a simple web app using Streamlit in under 100 lines of code. Now, it’s your turn to come up with an exciting project idea and turn it into reality!
It’s truly amazing how modern tools allow us to create complex applications in just a few hours. Even without extensive programming knowledge, proficiency in Python, or a deep understanding of machine learning, you can quickly build something useful and automate some tasks.
Don’t hesitate to ask me questions if you’re a beginner and want to create a similar project. I’ll be more than happy to assist you and respond as soon as possible. Best of luck with your projects!
Resources
Here are my other articles about LLMs that may be useful to you. I have already covered:
Estimating the Scale of Large Language Models: what are LLMs, how are they trained, and how much data and computing do they need;
Using ChatGPT for Debugging: how to use LLMs for debugging and code generation.
You can be also interested in:
Free Learn Prompting course to gain a deeper understanding of prompting and various techniques associated with it;
Recently released short courses by DeepLearning.AI to build applications with OpenAI API